Using custom models#
[1]:
import logging
from sklearn.datasets import load_diabetes
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from pprint import pprint
import hundred_hammers as hh
from hundred_hammers.model_zoo import DummyRegressor, Ridge, DecisionTreeRegressor
import warnings
from sklearn.exceptions import ConvergenceWarning
Let’s say you have discovered the best machine learning model ever, the “free lunch” everyone seems to be talking about (check the no free lunch theorem for machine learning for more information).
If you want to compare it to other models, it should be implemented as an scikit-learn style model, implementing at least the methods fit, predict and set_params.
We have not found such a model yet, so we will use a modified version of a Ridge model as an example.
[2]:
class InverseRidge(Ridge):
"""
A newly defined machine learning model.
Ridge regressor with alpha defined as 1/c.
"""
def __init__(self, c=1):
# It is important to add the parameter as an attribute of the class
self.c = c
super().__init__(alpha=1 / c)
# The following methods are not needed but are shown as an example of how to implement them.
def fit(self, X, y):
# Returns the trained model.
return super().fit(X, y)
def predict(self, X):
# Returns an array.
return super().predict(X)
# If the class inherits from BaseEstimator, this doesn't need to be implemented.
def set_params(self, **params):
# Returns the configured model.
return super().set_params(**params)
This new example model has a single real valued hyperparameter named “c” that has values higher than 0.
If we want grid search to automatically generate a grid of parameters for this new model, its definition must be added to the knowledge base of this library.
The hyperparameter definitions of all registered models are stored in the dictionary known_hyperparams.
We can show a couple of examples
[3]:
# Take a sample of model definitions
hyper_defs = hh.known_hyperparams[11:14]
# pretty print each of them
for i in hyper_defs:
pprint(i, sort_dicts=False)
print()
{'model': 'SGDClassifier',
'penalty': {'type': 'categorical',
'values': ['l1', 'l2', 'elasticnet', 'None']},
'alpha': {'type': 'real', 'min': 0, 'max': 100},
'l1_ratio': {'type': 'real', 'min': 0, 'max': 1}}
{'model': 'Perceptron',
'penalty': {'type': 'categorical',
'values': ['l1', 'l2', 'elasticnet', 'None']},
'alpha': {'type': 'real', 'min': 0, 'max': 100},
'l1_ratio': {'type': 'real', 'min': 0, 'max': 1}}
{'model': 'PassiveAggressiveClassifier',
'C': {'type': 'real', 'min': 0, 'max': 100}}
To register our model in this structure, we must provide a dictionary with the name of the class that implements the model and each of the hyperparameters, indicating whether it is a real number, an integer or a categorical value (a parameter that can take only a given set of values).
We must specify the bounds of each parameters by setting a minimum value and a maximum except for categorical parameters, for which we will specify the allowed values.
[4]:
# Define the hyperparameters of the model
inverse_ridge_def = {
"model": "InverseRidge",
"c": {"type": "real", "min": 1e-10, "max": 100},
}
# Add them to the knowlege base
hh.add_known_model_def(inverse_ridge_def)
We can verify that it has been added to the structure.
[5]:
# Take the last registered model
new_model_def = hh.known_hyperparams[-1]
# Pretty print it
pprint(new_model_def, sort_dicts=False, width=60)
{'model': 'InverseRidge',
'c': {'type': 'real', 'min': 1e-10, 'max': 100}}
Now that we have added or new model, we can use as another machine learning model without worrying about it.
[6]:
hh.hh_logger.setLevel(logging.WARNING)
data = load_diabetes()
X = data.data
y = data.target
models = (
("Dummy Regressor", DummyRegressor(), {}),
("Inverse Ridge", InverseRidge(), {}),
("Decision Tree", DecisionTreeRegressor(), {}),
)
# Create the model
hh_models = hh.HundredHammersRegressor(models=models)
# Evaluate the model
df_results = hh_models.evaluate(X, y, optim_hyper=True, n_grid_points=4)
# Print the results
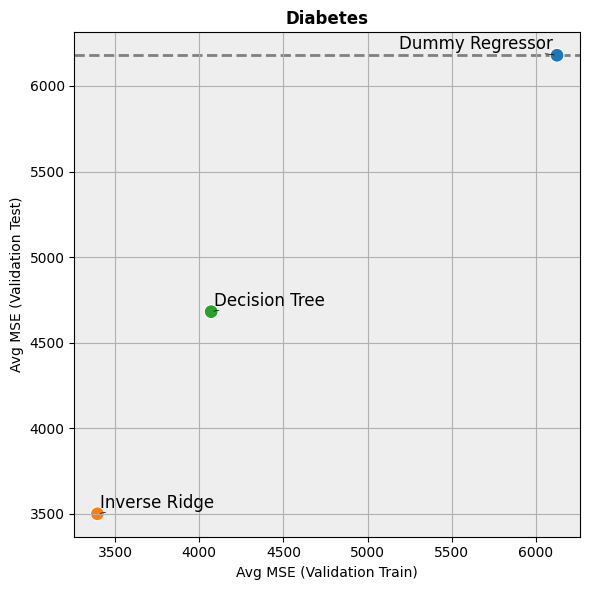
display(df_results)
| Model | Avg R2 (Validation Train) | Std R2 (Validation Train) | Avg R2 (Validation Test) | Std R2 (Validation Test) | Avg R2 (Train) | Std R2 (Train) | Avg R2 (Test) | Std R2 (Test) | Avg MSE (Validation Train) | ... | Avg MSE (Test) | Std MSE (Test) | Avg MAE (Validation Train) | Std MAE (Validation Train) | Avg MAE (Validation Test) | Std MAE (Validation Test) | Avg MAE (Train) | Std MAE (Train) | Avg MAE (Test) | Std MAE (Test) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Dummy Regressor | 0.000000 | 0.000000 | -0.023206 | 0.033628 | 0.000000 | 0.000000e+00 | -0.001337 | 0.000000e+00 | 6125.118931 | ... | 5134.783503 | 0.000000e+00 | 67.301695 | 1.188564 | 67.615074 | 3.943941 | 67.339534 | 1.421085e-14 | 59.227456 | 7.105427e-15 |
| 1 | Inverse Ridge | 0.445599 | 0.013815 | 0.419461 | 0.046400 | 0.465084 | 0.000000e+00 | 0.340980 | 5.551115e-17 | 3394.642031 | ... | 3379.406308 | 0.000000e+00 | 49.381703 | 0.756940 | 50.079365 | 3.114845 | 48.381085 | 7.105427e-15 | 46.566795 | 0.000000e+00 |
| 2 | Decision Tree | 0.335350 | 0.016310 | 0.221059 | 0.096463 | 0.326202 | 5.551115e-17 | 0.002965 | 0.000000e+00 | 4070.500515 | ... | 5112.723322 | 9.094947e-13 | 52.458085 | 0.997956 | 55.908937 | 3.478008 | 52.784358 | 0.000000e+00 | 57.041851 | 0.000000e+00 |
3 rows × 25 columns
[7]:
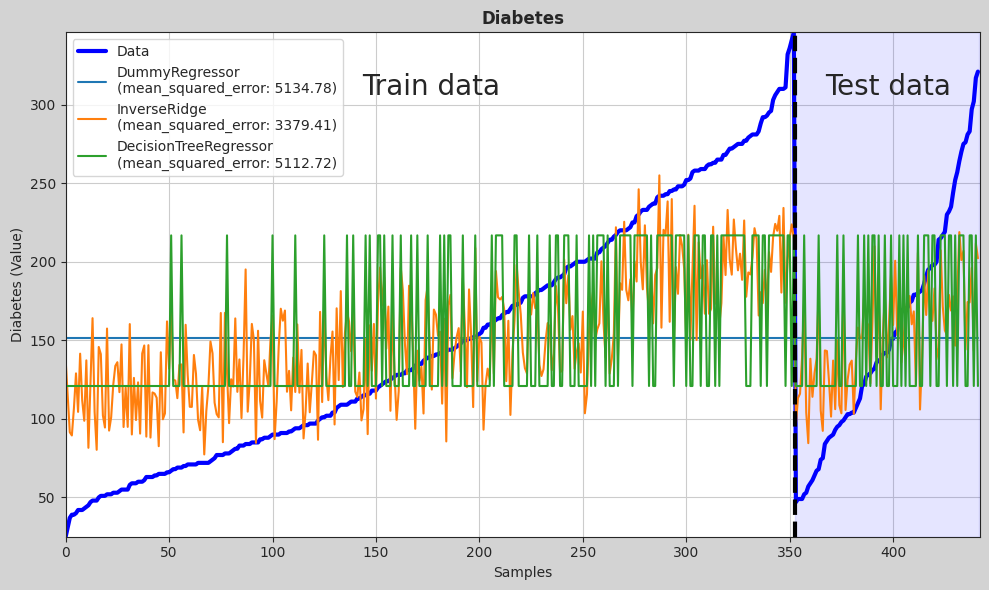
# Plot the results
hh.plot_batch_results(df_results, metric_name="MSE", title="Diabetes")
[8]:
models = [i for _, i, _ in hh_models.trained_models]
hh.plot_regression_pred(
X,
y,
models=models,
metric=mean_squared_error,
title="Diabetes",
y_label="Diabetes (Value)",
)